
SharePoint Syntex is artificial intelligence tool used to automate the extract of data from structured (or unstructured) documents. SharePoint sites can now use Syntex to conveniently upload and extract data automatically into document libraries. Then you can use the library content – and data – as you normal with as site information.
There’s a bit more to it just being “SharePoint” – there are some back-end Azure and PowerApps stuff going on (e.g. the Form Processing Model), but generally speaking the Syntex part – and for the general license – will be for “unstructured” documents.
- Convenience
- Automation
- Saving Time
Syntex is really good for letting “SharePoint do the work” instead of yourself or your users have to add documents and update document library columns with metadata. Those columns can be filled in based on data inside the document.
This is essentially a form of automation – reducing the manual work and letting a “smart” system do this bit for you.
Syntex can also be a really good time saver, especially if you’re bulk uploading like-minded documents and don’t want to spend hours classifying them.
In the long-run, this may save you and your organization time and money.
You’ll have to buy a specific license from Microsoft in your M365 tenant – one for each user that intends to build, maintain and use the Syntex AI models. This can be done from the Admin Center in the Purchase Services screen listed under the Billing accordion in the Navigation area (the license is technically under the “Add Ons” category as of this blog post publishing). You’re looking at about $5 USD per month, per license, and it’s only available to existing E3 and E5 users. If you have over 300 Syntex licenses, you are automatically 1 million AI Builder credits.
Microsoft advertises that you need a license for each user who is basically a “stakeholder” of Syntex. This is to say, if you have five people all building models and using Syntex content, they would each need a Syntex license. In reality, that doesn’t appear to be entirely correct. If you are a global admin and want to just use a document library with Syntex-provided content, it appears to work as normal without a Syntex license. I may not be able to build a model, but I can get to the content (although I am a Global Admin in my tenant). Either way, it’s best to get at least one license so you can actually build the AI models with your documents.
Here’s a tip – if you have a user in your tenant just for technical and configuration things (like a “service account” user) it’s probably more cost-effective to buy one license for this user account. As regular users, it appears one can still enjoy the benefits of Syntex just by browsing/using the document library that Syntex is applied to. That, however, may change in the future.
Syntex will need a Content Center to actually build the processing models you want. But once they’re built, you can assign the models to document libraries on any of your sites that you have access to in your tenant (as long as their modern team or communication sites).
Once that’s set up, you can visit the document libraries with the applied model and handle the processing at that location (how it kicks off can be handled either manually or automatically. Power Automate can be used to help automate this process).
After purchasing the license, you’ll have to assign it to your users.
Once that is done, you’ll need to perform a series of configuration steps in the Microsoft 365 Admin Center for your tenant.
Rather than write exact copies of this information, you can find step-by-step instructions by Microsoft at their Setup SharePoint Syntex Page on the Microsoft Documentation website.
There’s basically four steps to getting a model created – and they’re all performed on your newly created Content Center SharePoint site.
- Add Example Files
Upload the documents you want Syntex to process. Do this one document type at a time. - Classify Files and Run Training
Add labels to the example files so the model knows what type of document to classify it as. Provide explanations to refine that accuracy. - Create and Train Extractors
Train the model to identify what to look for inside the files (“extractors”). Use explanations to refine that accuracy again. - Apply Model to Libraries
Choose the document libraries across the sites in your tenant to use the new model.
Once the model is set up and applied to the library, users can add documents to the library as per usual. The user can then run the AI component manually (through a button in the GUI):
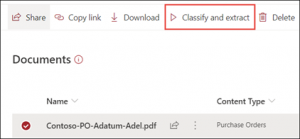
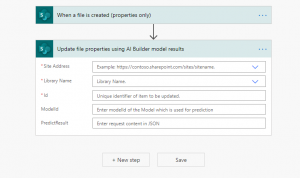
Or have Power Automate run it upon upload. I recommend getting familiar with Power Automate workflow creation and the associated triggers and actions, including reviewing your business processes and seeing where this automation might fit in.


0 Comments
Leave A Comment